Nested loop join appears like the simplest thing there could be — you go through one table, and as you go, per each row found you probe the second table to see if you find any matching rows. But thanks to a number of optimizations introduced in recent Oracle releases, it has become much more complex than that. Randolf Geist has written a great series of posts about this join mechanism (part 1, part 2 and part 3) where he explores in a great detail how numerous nested loop optimization interact with various logical I/O optimizations for unique and non-unique indexes. Unfortunately, it doesn’t cover the physical I/O aspects, and that seems to me like the most interesting part — after all, that was the primary motivation behind introducing all those additional nested loop join mechanism on the top of the basic classical nested loop. So I conducted a study on my own, and I’m presenting my results in the mini-series that I’m opening with this post.
Overview
The three mechanisms for nested loop joins are:
- classical (pre-9i, no optimizations)
- prefetch (9i, 10g)
- batching (11g and on)
In 12c, we could add another item to this list: batch rowid (even though, strictly speaking, it’s not necessarily related to nested joins — you can also see it a statement without any joins at all).
All these different implementations can be recognized by different plan shapes (classical single nested loop, a single nested loop with external TABLE ACCESS BY ROWID for the prefetch, a double nested loop for batching, and TABLE ACCESS BY ROWID (BATCHED)) for the 12c rowid batched mechanism). However, the shape of the plan should not be trusted blindly as Oracle appears to be keeping track of efficiency of those optimizations internally, so it’s possible that it could switch from the method shown in the plan to another without any warning. The specific choice of a nested loop method can be controlled by using hints and parameters — if you’re interested, you can find detailed information elsewhere (Randolf’s blog post series mentioned above would be a great place to start).
One thing all nested loop optimizations have in common in the use of multiblock reads to minimize the cost of the random reads (typically for TABLE ACCESS BY ROWID, which is often the most expensive step in a nested loop join; but it’s also possible for the index scan itself).
So this is what we already know, our “baseline” so to say.
Experimental setup
Even without going into too much detail, this section took more place than I’d like it to, so if you’re only interested in the results, feel free to skip this section altogether.
I’ve conducted my study on a VirtualBox machine based on publicly available (e.g. here) Oracle DB Developer VM with Oracle Linux 7.2 and pre-installed Oracle Database server 12.1.0.2.
Nested loop optimizations often get disabled when trying to observe them (e.g. when enabling rowsource statistics or turning SQL tracing on). Because of that, I had to resort to non-intrusive tracing methods heavily based on awesome systemtap scripts developed by Luca Canali (see e.g. here and here).
For simplicity, I used the same driving table for all use cases, and the set of “driven” tables was created using this script:
create table &tabname(id number, padding varchar2(4000), x number);
insert into &tabname
select level id,
rpad(' ', &pad, dbms_random.string('a', 1)) padding,
trunc(dbms_random.value(0,10)) x
from dual
connect by level <= 100000 order by case when dbms_random.value(0, 100) > &rand then id
else dbms_random.value*1e5 end;
“Pad” and “rand” parameters (for “padding” and “randomization”) control row density per block and the index clustering factor, respectively. I used 10, 100, 1000, 4000 for padding (the last one means that the block would contain only 1 row), and 0, 1, 10, 20, 50, 100 for rand.
To avoid undesirable effects I disabled filesystem caching (filesystemio_options => directio), adaptive optimizer features (as it caused some very noticeable overhead — see e.g. here for details), buffer cache warmup prefetch (_db_cache_pre_warm => false) and dynamic sampling (optimizer_dynamic_sampling => 0). I have a also set _small_table_threshold to a low value (100) to make sure that the driving table is scanned via direct reads (which made it easier to distinguish those reads from buffered reads coming from the index probes).
Results
Mechanism
For the most part, optimized nested loops were performed with the use of non-contiguous multiblock reads (“db file parallel read” event). Only 3 test cases out of 112 were contiguous multiblock reads observed, but even there non-contiguous reads were still the majority.
The blocks read in “db file parallel read” events were ordered (or at least piece-wise ordered in large chunks of increased addresses), even when the data themselves weren’t. Below is shown an exerpt from systemtap output as an example (event#=158 means “db file parallel read” as you can find from v$event_name):
DB WAIT EVENT END: timestamp_ora=72901638523, pid=2130, sid=259, name=KARAMUL, event#=158, p1=1, p2=39, p3=39, wait_time=85915, obj=105128, sql_hash=832393409 ========== ->kcbzvb, Oracle has performed I/O on: file#=10, block#=40579, rfile#=9, bigfile_block#=37789315 ->kcbzvb, Oracle has performed I/O on: file#=10, block#=40582, rfile#=9, bigfile_block#=37789318 ->kcbzvb, Oracle has performed I/O on: file#=10, block#=40587, rfile#=9, bigfile_block#=37789323 ->kcbzvb, Oracle has performed I/O on: file#=10, block#=40589, rfile#=9, bigfile_block#=37789325 ->kcbzvb, Oracle has performed I/O on: file#=10, block#=40590, rfile#=9, bigfile_block#=37789326 ...
We can use the trick I described earlier to see which rows these blocks correspond to:
select t.id, x.blockno
from nl_rand50_pad4000 t,
(select 40579 blockno from dual union select 40582 from dual union select 40587 from dual union select 40589 from dual union select 40590 from dual) x
where dbms_rowid.rowid_block_number(t.rowid) =x.blockno
order by x.blockno;
and confirm that the logical data ordering is not observed:
id blockno =============== 2 40579 5 40582 14 40587 9 40589 10 40590
This is obviously intended to minimize seek time when performing the random I/O, although it’s probably not very helpful when the data is on a flash storage (since physical ordering doesn’t have meaning there), or when a spinning disk array has its own low-level optimizations of the same kind (elevator optimizations, read-ahead etc.).
As far as I can see, this ordering took place in all test cases where db file paralled read events were used, regardless to the specific method of nested loop optimizations.
Multiblock read count
It is also quite instructive to look at the actual multiblock read count (MBRC) used in db file parallel read depending on the specific optimization mechanism employed. I summarized the results in 3 plots below. For clarity, I plotted MBRC vs the actual clustering factor of the index normalized to the number of rows. There are only 3 plots, because for pad=4000 the normalized clustering factor is always 1 so the x range collapses into single point.
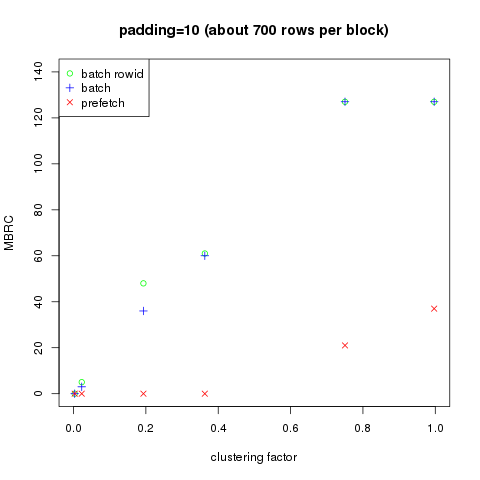

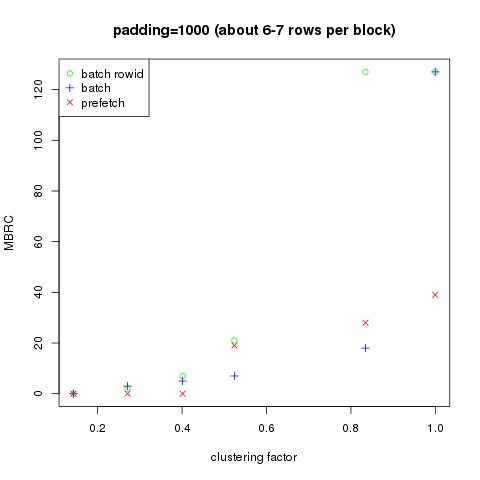
As we can see, the larger the clustering factor (i.e. the less ordered the data is) the more aggressively Oracle is using multiblock reads, which makes perfect sense. For high row density the “batch” and “batch rowid” optimizations behave very similarly, but for lower row density this is no longer the case, which indicates that the mechanisms behind those optimizations are distinct.
We can also see that the old “prefetch” mechanism is generally less aggressive. Unlike batch optimizations, it has a certain “inertia”, i.e. it’s only enabled after a certain threshold is crossed, and it appears to be capped at a relatively low level — in all test cases I have never see it go above 39, about a third of the maximum MBRC value for batch optimizations (127).
All in all, prefetch seems to behave in a more step-like fashion with a low MBRC limit, while batch optimizations adjust to the degree of data set ordering in a more flexible way, starting at low MBRC values for ordered data set and monotonously growing to a much higher value for unordered data sets.
Summary
We saw that systemtap can be used for understanding low-level optimization of Oracle nested loop joins. For the test cases considered, this optimization mostly takes place as non-contiguous multiblock reads (“db file parallel read” event). For older prefetch mechanism, the multiblock read count seems to be generally lower and is limited by the maximum value of 39, while for batch and batch rowid mechanisms it reached 127.

3 thoughts on “Nested loop internals”